
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 데이터분석가
- 유데미부트캠프
- SQL
- 회고록
- 데이터시각화
- 2024년
- 취업부트캠프
- 프로그래머스
- 자격증준비
- 프리온보딩
- 자격증
- tableau
- 프로젝트
- 실습
- 스타터스부트캠프
- 코테
- 유데미
- 태블로
- 파이썬
- Tableau Desktop Specialist
- trouble shooting
- 유데미코리아
- 부트캠프후기
- 쿼리테스트
- MySQL
- AICE
- 러닝스푼즈
- 코딩테스트
- Python
- 데이터분석
- Today
- Total
신이 되고 싶은 갓지이
2. Python 기초 - Pandas를 통해 데이터 병합하고 정리, 집계하기 본문
1. 데이터 추가하기
- df['컬럼명'] = data
※ data에 들어갈 수 있는 것
1) 하나의 값: 전체 모두 동일한 값
2) 그룹: 리스트, 판다스의 시리즈
※ 새로운 컬럼을 만들 경우에는 df.컬럼명 = data 형태는 사용 불가. (df['컬럼명'] 으로만 가능)
data['음악'] = 90 # 동일한 값 입력
data.head()
data['체육'] = [100, 80, 60] # 각 행에 서로 다른 값 추가
data.head()
# 컬럼간의 사칙연산으로 새로운 컬럼 생성 가능
data['국영수 평균'] = (data['국어'] + data['영어'] + data['수학'] ) / 3
data.head()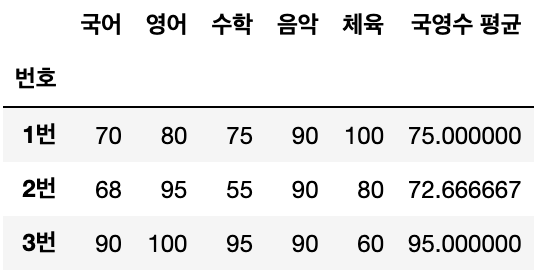
2. 데이터 표 병합하기
- pd.merge(A, B, how = 'left', left_on = '컬럼명', right_index = True)
1) how
- left(왼쪽 표 기준)
- right(오른쪽 표 기준)
- inner(A,B 둘 다 있는 데이터만)
- outter(A,B 한쪽이라도 있는 데이터)
2) left_on/right_on : 병합 기준 컬럼 지정
3) left_index/right_index = True : 병합 기준 인덱스로 지정
4) on : A & B 같은 이름의 열을 기준으로 지정할 경우
# 첫번째 데이터 불러오기
fpath = './data/exam.xlsx'
A = pd.read_excel(fpath, index_col = '번호')
A.head()| 국어 | 영어 | 수학 | |
|---|---|---|---|
| 번호 | |||
| 1번 | 70 | 80 | 75 |
| 2번 | 68 | 95 | 55 |
| 3번 | 90 | 100 | 95 |
# 두 번째 데이터 불러오기
fpath2 = './data/exam_extra.xlsx'
B = pd.read_excel(fpath2, index_col = '번호')
B.head()| 과학 | 사회 | |
|---|---|---|
| 번호 | ||
| 1번 | 70 | 80 |
| 2번 | 80 | 85 |
| 4번 | 95 | 100 |
| 5번 | 90 | 70 |
# 엑셀의 Vlookup 처럼 합쳐보기
# A, B 테이블을 A테이블에 있는 키값을 기준으로,
# A 테이블은 인덱스를 키 값으로, B 테이블은 인덱스를 키 값으로 병합
total = pd.merge(A, B, how = 'left', left_index = True, right_index = True)
total.head()| 국어 | 영어 | 수학 | 과학 | 사회 | |
|---|---|---|---|---|---|
| 번호 | |||||
| 1번 | 70 | 80 | 75 | 70.0 | 80.0 |
| 2번 | 68 | 95 | 55 | 80.0 | 85.0 |
| 3번 | 90 | 100 | 95 | NaN | NaN |
# A, B 테이블을 B테이블에 있는 키값을 기준으로,
# A 테이블은 인덱스를 키 값으로, B 테이블은 인덱스를 키 값으로 병합
pd.merge(A, B, how = 'right', left_index = True, right_index = True)| 국어 | 영어 | 수학 | 과학 | 사회 | |
|---|---|---|---|---|---|
| 번호 | |||||
| 1번 | 70.0 | 80.0 | 75.0 | 70 | 80 |
| 2번 | 68.0 | 95.0 | 55.0 | 80 | 85 |
| 4번 | NaN | NaN | NaN | 95 | 100 |
| 5번 | NaN | NaN | NaN | 90 | 70 |
# A, B 테이블 양쪽에 모두 존재하는 키 값을 기준으로,
# A 테이블은 인덱스를 키 값으로, B 테이블은 인덱스를 키 값으로 병합하겠습니다.
pd.merge(A, B, how = 'inner', left_index = True, right_index = True)| 국어 | 영어 | 수학 | 과학 | 사회 | |
|---|---|---|---|---|---|
| 번호 | |||||
| 1번 | 70 | 80 | 75 | 70 | 80 |
| 2번 | 68 | 95 | 55 | 80 | 85 |
# A, B 테이블을 A, B 테이블 양쪽에 한번이라도 존재하는 모든 키 값을 기준으로,
# A 테이블은 인덱스를 키 값으로, B 테이블은 인덱스를 키 값으로 병합하겠습니다.
pd.merge(A, B, how = 'outer', left_index= True, right_index=True)| 국어 | 영어 | 수학 | 과학 | 사회 | |
|---|---|---|---|---|---|
| 번호 | |||||
| 1번 | 70.0 | 80.0 | 75.0 | 70.0 | 80.0 |
| 2번 | 68.0 | 95.0 | 55.0 | 80.0 | 85.0 |
| 3번 | 90.0 | 100.0 | 95.0 | NaN | NaN |
| 4번 | NaN | NaN | NaN | 95.0 | 100.0 |
| 5번 | NaN | NaN | NaN | 90.0 | 70.0 |
3. 저장하기
- pd.to_excel('저장할 파일경로/파일명.xlsx', index = True)
*저장시 항상 인덱스를 저장하기 때문에 인덱스를 저장하고 싶지 않을때에는 저장시에 index = False 옵션을 사용
4. 데이터 정리/집계하기
- 집계하기 : pd.pivot_table(index = '컬럼명', columns = '컬럼명', values = '컬럼명', aggfunc = 'sum')
1) aggfunc 옵션: sum, count, mean, ...
* df.sum() 을 활용하면, 기본값으로 axis=0 으로 지정되며, 컬럼별 합계가 아닌 row 별 합계가 계산되며 axis=1으로 지정하면 컬럼별 합계가 된다.
import pandas as pdfile = './data/babyNamesUS.csv'
raw = pd.read_csv(file)# head() 를 이용해 상단의 5개 데이터를 살펴보기
raw.head()| StateCode | Sex | YearOfBirth | Name | Number | |
|---|---|---|---|---|---|
| 0 | AK | F | 1910 | Mary | 14 |
| 1 | AK | F | 1910 | Annie | 12 |
| 2 | AK | F | 1910 | Anna | 10 |
| 3 | AK | F | 1910 | Margaret | 8 |
| 4 | AK | F | 1910 | Helen | 7 |
# 1. 이름 사용 빈도수 집계하기
# state, 성별, 출생연도에 상관없이 이름이 등록된 수를 합하여 인덱스는 이름으로, 값은 등록된 수를 모두 더하여 피벗 테이블을 만들기
raw.pivot_table(index = 'Name', values = 'Number', aggfunc='sum')| Number | |
|---|---|
| Name | |
| Aadan | 18 |
| Aaden | 855 |
| Aadhav | 14 |
| Aadhya | 188 |
| Aadi | 116 |
| ... | ... |
| Zylah | 36 |
| Zyler | 38 |
| Zyon | 97 |
| Zyra | 23 |
| Zyrah | 5 |
20815 rows × 1 columns
# 2. 이름/성별 사용 빈도수 집계하기
# 앞서 생성한 데이터에서, 성별 구분을 컬럼에 추가하여 인덱스는 이름으로, 값은 등록된 수의 합계, 컬럼은 성별로 구분하여 피벗 테이블을 만들기
name_df = raw.pivot_table(index = 'Name', values = 'Number', columns = 'Sex', aggfunc='sum')
name_df.head()| Sex | F | M |
|---|---|---|
| Name | ||
| Aadan | NaN | 18.0 |
| Aaden | NaN | 855.0 |
| Aadhav | NaN | 14.0 |
| Aadhya | 188.0 | NaN |
| Aadi | NaN | 116.0 |
# 성별/이름별 데이터는 총 20815개의 이름 데이터가 있으며
# 여자 이름은 14140개, 남자 이름은 8658 개의 데이터가 있는 것을 확인
name_df.info()<class 'pandas.core.frame.DataFrame'>
Index: 20815 entries, Aadan to Zyrah
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 F 14140 non-null float64
1 M 8658 non-null float64
dtypes: float64(2)
memory usage: 487.9+ KB
5. 비어있는 데이터 채우기
비어있는 데이터 처리 방법
- 공통된 값을 입력(ex 0)
- 임의의 수를 입력(ex 평균, 최대값, 최소값, 비어있는 자리 주변의 값 등)
- 비어있는 데이터는 분석에서 제외
# 숫자 0을 입력
name_df = name_df.fillna(0)
name_df.head()| Sex | F | M |
|---|---|---|
| Name | ||
| Aadan | 0.0 | 18.0 |
| Aaden | 0.0 | 855.0 |
| Aadhav | 0.0 | 14.0 |
| Aadhya | 188.0 | 0.0 |
| Aadi | 0.0 | 116.0 |
# 여자(F)와 남자(M) 컬럼 각각 20815개의 데이터를 가지며 전체 데이터 셋의 개수(인덱스 개수 20815개)와 동일한 것을 확인
name_df.info()<class 'pandas.core.frame.DataFrame'>
Index: 20815 entries, Aadan to Zyrah
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 F 20815 non-null float64
1 M 20815 non-null float64
dtypes: float64(2)
memory usage: 487.9+ KB
6. 정렬하기
- name_df.sort_values(by = '컬럼명', ascending = False)
# 오름차순으로 정렬
name_df.sort_values(by = 'M')| Sex | F | M |
|---|---|---|
| Name | ||
| Kasandra | 2130.0 | 0.0 |
| Lillyanna | 442.0 | 0.0 |
| Lillyanne | 48.0 | 0.0 |
| Lillybeth | 5.0 | 0.0 |
| Lilou | 5.0 | 0.0 |
| ... | ... | ... |
| David | 2003.0 | 615943.0 |
| John | 2398.0 | 670893.0 |
| Robert | 2469.0 | 674934.0 |
| James | 3050.0 | 693271.0 |
| Michael | 4133.0 | 725757.0 |
20815 rows × 2 columns
# 내림차순으로 정렬
name_df.sort_values(by = 'M',ascending = False)| Sex | F | M |
|---|---|---|
| Name | ||
| Michael | 4133.0 | 725757.0 |
| James | 3050.0 | 693271.0 |
| Robert | 2469.0 | 674934.0 |
| John | 2398.0 | 670893.0 |
| David | 2003.0 | 615943.0 |
| ... | ... | ... |
| Jemimah | 5.0 | 0.0 |
| Jemma | 535.0 | 0.0 |
| Jena | 1819.0 | 0.0 |
| Jenae | 510.0 | 0.0 |
| Zyrah | 5.0 | 0.0 |
20815 rows × 2 columns
# 남자이름 사용순위 Top 5
name_df.sort_values(by = 'M',ascending = False).head().indexIndex(['Michael', 'James', 'Robert', 'John', 'David'], dtype='object', name='Name')# 여자이름 사용순위 Top 5
name_df.sort_values(by = 'F',ascending = False).head().indexIndex(['Mary', 'Jennifer', 'Elizabeth', 'Patricia', 'Linda'], dtype='object', name='Name')
7. 컬럼별 데이터 종류 확인해보기
- 데이터 종류 : df['컬럼'].unique()
- 데이터 갯수 : df['컬럼'].value_counts()
# StateCode 컬럼에 어떠한 값이 들어있는지 확인
raw['StateCode'].unique()array(['AK', 'AL', 'AR', 'AZ', 'CA', 'CO', 'CT', 'DC', 'DE', 'FL'],
dtype=object)# StateCode 컬럼의 값의 종류별로 몇 번 사용되었는지 확인
raw['StateCode'].value_counts()StateCode
CA 361128
AL 128556
AZ 108599
CO 101403
AR 97560
CT 78039
FL 61322
DC 53933
DE 30892
AK 27143
Name: count, dtype: int64# 연도별 데이터 수를 확인
raw['YearOfBirth'].value_counts()YearOfBirth
2007 17166
2008 17109
2009 16914
2014 16820
2006 16810
...
1914 3997
1913 3417
1912 3148
1911 2392
1910 2358
Name: count, Length: 106, dtype: int64'Python' 카테고리의 다른 글
| 4. Python 기초 - 데이터 분석시 자주 발생하는 error의 trouble shooting (4) | 2024.01.09 |
|---|---|
| 3. Python 기초 - Seaborn, Folium으로 시각화 하기 (4) | 2024.01.05 |
| 1. Python 기초 - Pandas에 대한 기본 사용법 정리 (3) | 2024.01.02 |
| [python 실습] 아파트 실거래 분석, 시각화 실습 (1) | 2023.03.10 |
| [python 실습] 인구데이터를 통한 분석 실습 (1) | 2023.03.10 |


